So you want to show off the size of your dictionary? Look no further than this quick test, which will work out how many words you know.
Just click the word that’s closest in meaning to travel (n.). As you play we’ll narrow down the estimate of your vocabulary size, and you can stop whenever you get bored. Right now we think you know about 2,000 words (between 400 and 200,000).
You can also administer the test for someone else. For more reliable results, try asking them to define the word or give an example. If they are not sure of a word then just click an answer at random.[1]
How it works
We can’t test you on every English word – there are hundreds of thousands of them. Instead we can turn this into a statistical problem, by asking how likely you are to know a given word. If there’s a 5% chance you’ll recognise any word in English, that means you know a twentieth of the dictionary, and we can figure out your vocabulary size from there.
Ideally we’d show you a small sample of words, chosen at random, and see what fraction you understand. But the way words are distributed in English makes this tricky. The plot below shows the top 50, ordered by how often they appear in writing. You can see that a few of them (like the and and) are really popular, while the rest are less well used.
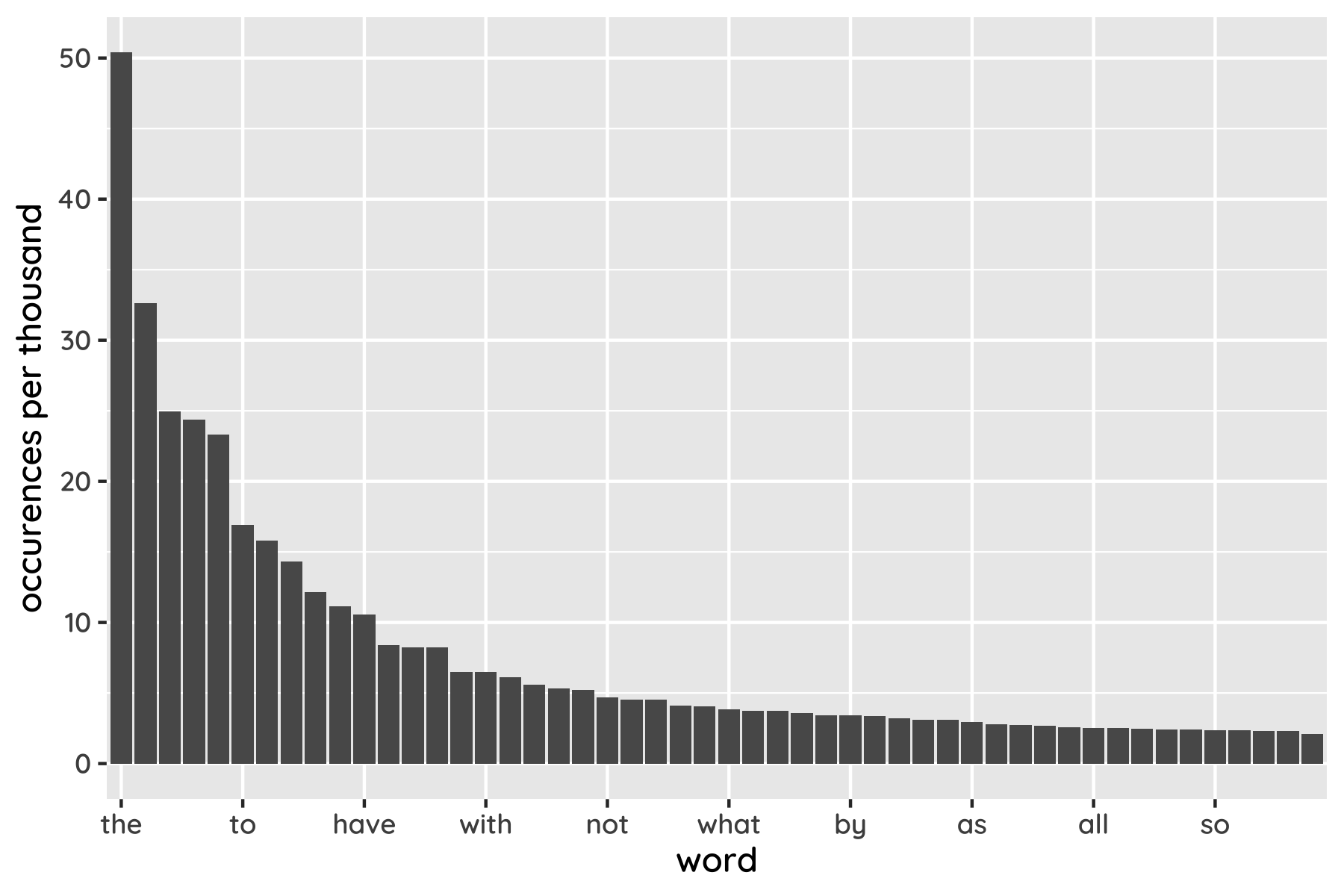
That pattern persists as we look down the list. However many words we include, there are a always a small number of celebrities and a lot of proletarians. Zooming out, English has a few thousand widely-used words, tens of thousands of unusual ones, and millions more that are esoteric, archaic or obsolete.
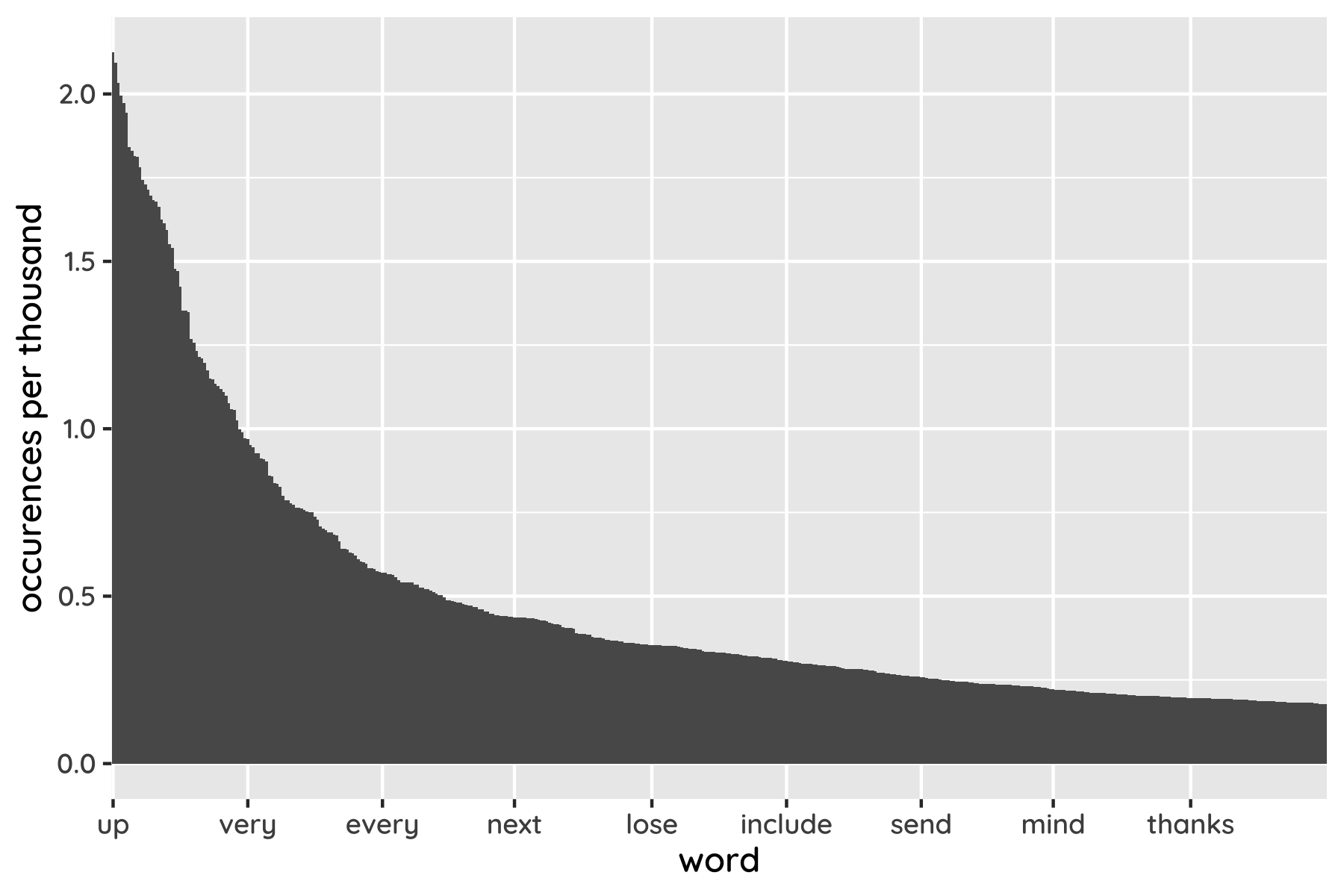
The upshot is that a quiz based on randomly sampled words would be tedious, because almost all of them would be obscure beyond recognition. To avoid that we have to be a bit cleverer.
The shape of this graph can also be to our advantage. It shows that a word twice as far down the list gets used roughly half as often, an effect known as Zipf’s law. So a word’s rank gives an idea of its popularity, which in turn affects how likely you are to recognise it. That makes it possible to talk about your confidence in different parts of the list, separating the common and uncommon words, rather than dealing with all of them at once.
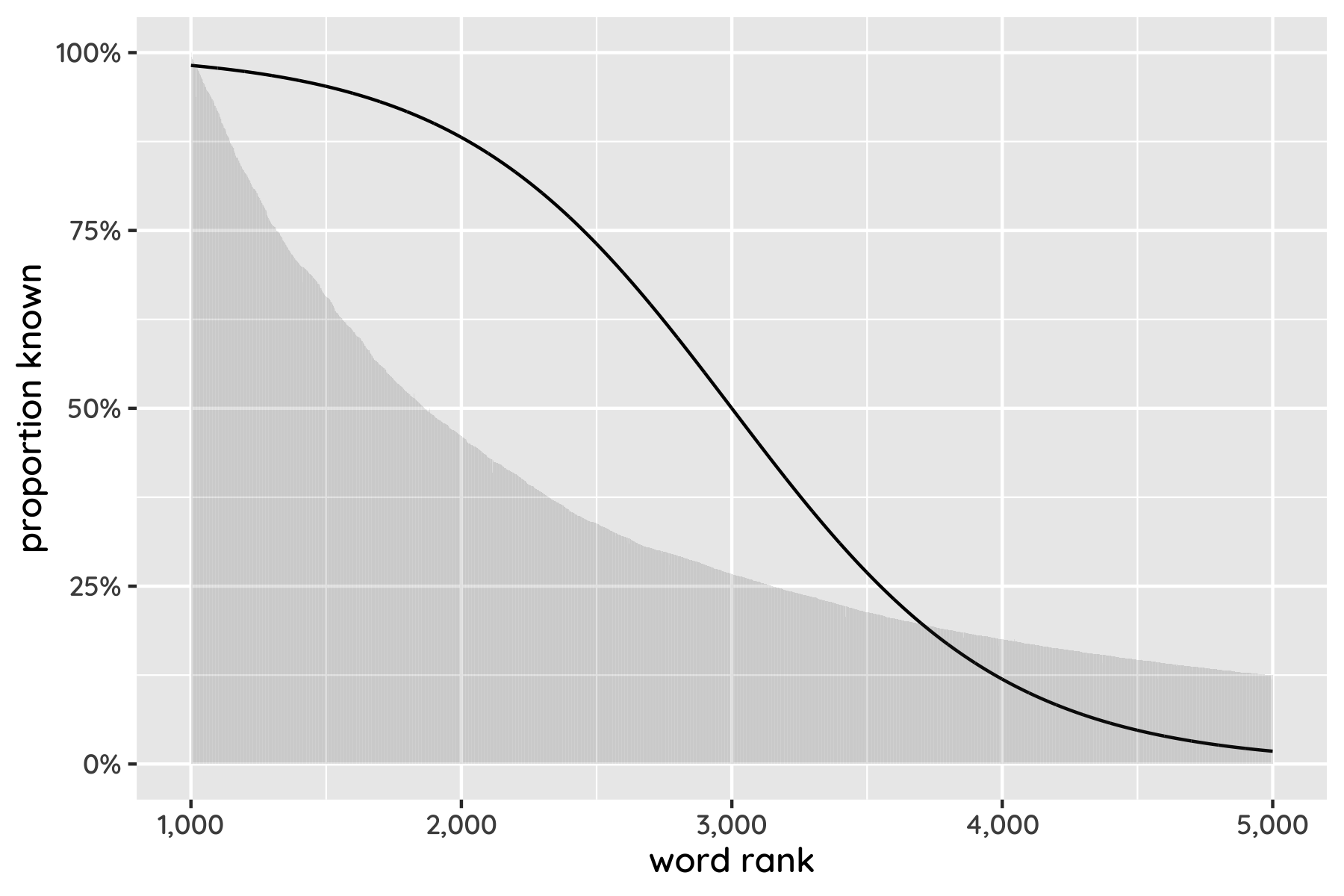
This plot shows what someone’s “vocab curve” might look like – that is, the proportion of words they recognise in different parts of the list. The upside-down-S shape represents someone who knows almost all the common words, some unusual ones, and few arcane ones. Everyone’s curve will be different, but if we can find yours roughly, we know your chance of recognising every word in English. Then we can count up the total.
Armed with word frequency data from COCA and a bit of mathematical jiggery-pokery, that’s exactly what this test does. As we learn which words you understand, we can narrow down what this curve looks like for you, and so estimate your vocabulary size.
The only question is how to probe your knowledge. Some tests simply ask if you recognise a set of words, but this probably leads to overestimates. Obscure words can be mistaken for common ones (eg dissemble for disassemble, or lessor for lesser). Multiple choice is more objective at the cost of introducing false positives – because if you guess at random, you’ll be right a quarter of the time. Luckily this is easy to adjust for in the statistics.
One snag of that approach is that some obscure words are guessable. You can probably assume that jurist has something to do with the courts, for example, even if you don’t know it means “an expert in law” specifically. Unless you are a microbiologist or doctor you may not know many names for bacteria or diseases, but they tend to follow a recognisable template. A fair few of these words can simply be removed from the quiz, and the result is reasonable for the level of effort needed to put it together.[2]
On vocab size
You can’t count words without deciding what qualifies as one. Datasets like COCA usually make an effort to “stem” words, so that jumps, jumping, jumped and so on are all treated as variations on the same root, jump. In this case it’s clear that there’s really just one verb, alongside generic rules for conjugation which only need to be learned once. But in general it’s hard to decide whether a word is distinct or a variation, leading to some level of arbitrariness. We follow the decisions of Merriam-Webster, including only their dictionary headwords.[3]
Possibly the best-known existing test is testyourvocab.com (TYV), which may give slightly lower scores than this one. Although there are differences in method, probably far more significant is the underlying data used. TYV’s, drawn from the British National Corpus, is over a decade old. Because we use a larger and more modern lexicon, we can detect more of your hard-earned words.
Languages change. The Oxford English Dictionary added 1400 new entries just in the first quarter of 2021. A corpus drawn from the internet, rather than stuffy 20th century news and literature, has less Queen’s English and more memespeak. Our data source includes neologisms (like blog), some homonyms (mean as in intend, average and unkind),[4] hyphenations (like co-founder) and some fandom terms like turbolift (from “Star Wars”). So TYV’s hardest words are more obscure than those from the newer list, even though the latter has more entries overall.
Many words don’t appear in the older corpus even once. Future linguists will no doubt learn a lot about our changing society from terms like blog, ipad, self-driving, idiot-proof and co-wife.
Maths
Say is the popularity of the word, and is true if you know the word. The statistical model is as follows.
This is a probit regression (much like the more common logistic regression, but with slightly better fit to this data). Basically, and are learnable parameters that define an S-shaped curve, and we can fit that curve to your quiz answers.
We could equally write the model with an explicit Bernoulli distribution and the normal distribution CDF .
This isn’t quite the whole story, though, because we don’t actually see (whether you know the word) but (whether you got the answer right). With multiple choice these are quite different things, because there’s a one in four chance you’ll get the answer by guessing.[5]
We can easily tweak the model to deal with this, observing but then recovering to calculate your score. The quiz uses Expectation Propagation to fit the model in your browser (this happens in the time between clicking an answer and a new question appearing). Running the model live lets us make use of its results on the fly: we can ask questions for which the chance of a right answer is about 50%. Words at the edge of your knowledge – not too easy, not too hard – are the most helpful for fitting the curve, as well as being more fun to answer.
After fitting we can pull out a function representing how likely it is that you know any word at rank . Then it’s easy to sum up over all word ranks to estimate how many you know overall.[6]
Note that we’ve assumed there are more words than just those in our limited dataset, which only goes up to rank 40,000. Summing to infinity equates to including the top million words in English (or some other big number).
It’s a little bold to model your knowledge beyond the words that we can test. It’d be useful to bolster our assumptions by checking the fit more thoroughly, especially using data from smaller vocabularies (like those of youngsters or non-native speakers). That said, it won’t have a big effect on most people’s results, and the alternative of capping high scores is no less arbitrary.
Infinity could even be the right choice in principle. András Kornai has argued that the size of language is actually unbounded. Zipf’s long tail just keeps going on, leaving no expression out, however few people use it. It includes those that live among odd dialects in remote villages; those that were made up by toddlers or as an inside joke between friends; those that are only spoken playfully over pillows. We may as well count them, too.
If your subject gets a word wrong, it’s best not to knowingly choose a wrong answer on their behalf. The reason is that the quiz expects you to get some answers right by accident, so forcing wrong answers could make it overly pessimistic. ↩︎
A better approach would be to have participants choose between a set of plausible-sounding definitions for the given word. But for several thousand words this would be labour-intensive to build. (Collecting synonyms was already more work than you’d think – it turns out to be hard to automate.) ↩︎
COCA contains some interesting redundant words, like greediness (more usually just greed), cohabitate (cohabit) and complicitous (complicit). It includes compounds like youthful-looking that are unusual but don’t need to be learned separately from their parts, and treats some spelling variants like bazar and bazaar separately. After filtering for dictionary headwords, about a third of the original dataset is removed. ↩︎
A limitation of the COCA dataset is that it only includes homonyms in different parts of speech (verb, noun and adjective in the case of mean). There is only one bank listed, even though riversides and financial institutions get separate entries in the dictionary. This will lead to some underestimation in the test. ↩︎
Incidentally, I think this is a nice case study in questioning statistical assumptions. You could certainly throw plain logistic (or probit) regression at this quiz data, and it’d give you an answer. But it’d be a poor one given that the distribution doesn’t actually fit ( doesn’t tend towards zero). A simple tweak, taking into account how the data is produced, gets much better results. ↩︎
The quiz also displays 95% confidence intervals, which are only slightly trickier to calculate. ↩︎