“Words can be like X-rays if you use them properly – they’ll go through anything.”
Wordle is a neat little word game, somewhere between mastermind and hangman. Try to guess the hidden five-letter word and it will tell you which letters are correct, and whether they are in the right position. You have six guesses to narrow down the right answer. Can we work out an automated strategy for this game?
To start with we need a set of words to work with. Wordle actually uses two lists: a shortlist of possible answers (2,315 words) and a longer list of valid guesses (10,657 words), making for 12,972 total. Implicitly those words are known to everyone who plays, because if you make a guess outside of the list, it’ll be rejected.[1]
Resident Wordle Controller
To make good guesses, we need to know what it means for a guess to be good, which means evaluating how well we’re doing as we play the game. The most obvious measure is the number of words remaining, which we want to be as low as possible. This is easy to work out: just look over all possible five-letter words and see how many fit the clues we’ve been given.
For example:
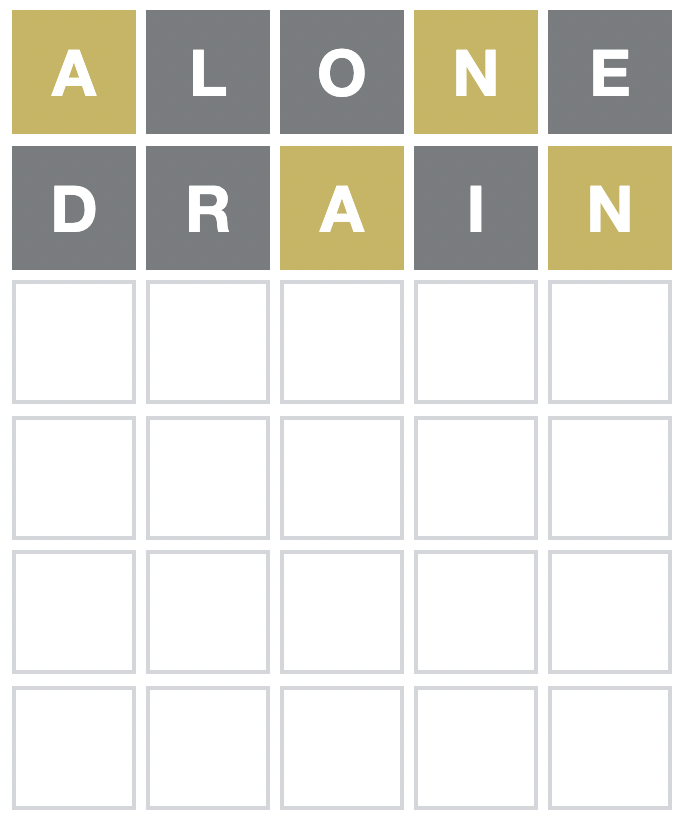
That may not look like great progress, but there are only seven words that fit (like nasty, manga and fancy), so we’re pretty close to getting the answer. The first guess, alone, left us with 40 possibilities, and drain has helped us narrow those down quite a bit – making it a useful guess.
We can make this a bit more formal using the concept of entropy, from information theory. If we have a list of words, each of which has probability of being correct, the entropy is
. A shortened list has more information about the correct answer, so by guessing “drain” above we gained bits of information. (If this seems like nonsense, I’ll give a more intuitive explanation below.)
Sharp-eyed readers will spot an issue: to work this out depends on making the guess and getting feedback from Wordle. But once we’ve made the guess, we can’t retract it and try out something else – that would be cheating. We need to evaluate the guess before we use it, not after.
We can do this by basically simulating Wordle ourselves. Say we started with alone. We don’t know the answer, but let’s assume for the sake of argument that it’s panic. If we (hypothetically) know that, we know what clues we’ll get after guessing drain. Then we can check how many words will be left over that match those clues (3 in this case), and the resulting information gain. If we repeat this for every possible answer and take the average, we’ll have a measure of how good of a guess drain is overall, independent of whatever the true answer might be.
If we then repeat this for each possible guess, we can choose the one that maximises the average information gain (or equivalently, minimises expected entropy). Of the 40 answers possible after guessing alone above, drain makes for the best guess (4 bits on average) and knack is the worst (2.3 bits on average).
All this about information theory might seem abstract, so here’s another way of explaining the same maths. Really we’re just cutting out as many words as possible with each guess; we do this by calculating how many words remain after the guess (averaged over every possible answer) and choosing the guess with the lowest score. From this point of view, drain is a good guess because it usually leaves us with fewer answers (2.5 on average – though remember we actually got 7 above, so were a bit unlucky) whereas knack leaves us with more (8.4 on average).
The only surprising thing is that we use the geometric mean, rather than the usual arithmetic mean, for the average – this is the effect of taking entropy into account.[2] Intuitively the geometric mean makes us take risks. Say we have two possible guesses we could make. One might leave us with either 10 remaining words or 100, with equal probability. The other will leave us with 55 words whatever happens.
| 10 / 100 | 55 / 55 | |
|---|---|---|
| Arithmetic mean | 55 | 55 |
| Geometric mean | 32 | 55 |
Using the arithmetic mean, these options are equivalent. But the geometric mean rates the first option as significantly better: the chance to narrow down the answer so much is worthwhile, even alongside the risk of learning nothing.[3]
You’re no doubt doing something similar to this when you play, albeit less algorithmically. You’ll probably guess a word with new, common letters before one that has redundant or obscure ones – provided you can think of one – which will help you get more information from Wordle’s response.
Words & X-Rays
One way our bot can help human players is to figure out the best starting word. This is the same problem: we want our first guess to rule out as many words as possible. It turns out the best common word (from the shortlist) is raise (5.88 bits, 39.4 remaining). But if you want to be cheeky you can use the questionable soare (5.89 bits, 39.1 remaining) for a slight edge.
Unsurprisingly, unusual or repeated letters tend to be unhelpful. Of the possible answers, the worst initial guess is mamma (2.3 bits, 480 remaining). If you want an extra challenge you can use qajaq (1.8 bits, 680 remaining), an unusual variant of kayak.
On that note, it’s important to point out that good guesses don’t have to be valid answers. If you run the entropy strategy it can make almost random-looking choices.
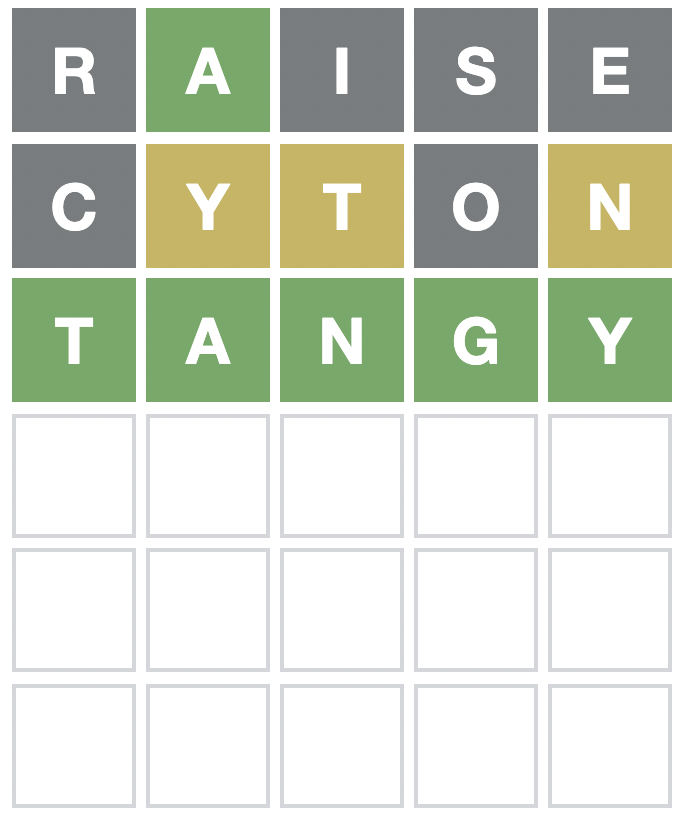
cyton can’t be the answer, but it’s effective at splitting the remaining words, in this case leaving only two options (tangy and tawny). This trick makes all the difference, allowing us to solve any word in six guesses or less.
Here’s how it does with the rest of the words:
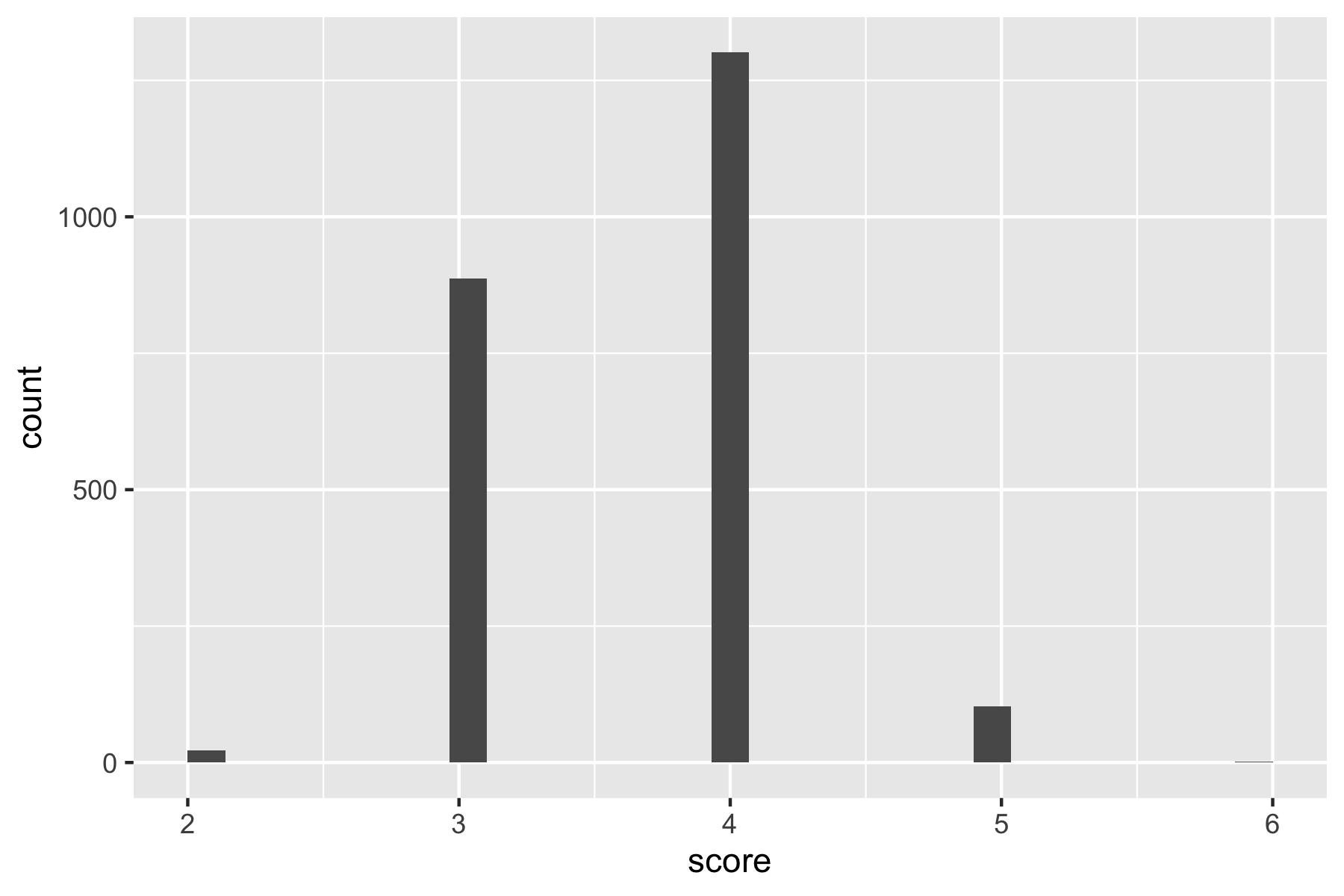
We can get a score of 3.4 on average, with over 95% of words solved in four or fewer guesses. Only two words (wafer and waver) need the full six guesses.
I’ve put my code on github. Can you beat it?
It’s debatable whether a Wordle bot should make use of the shortlist. On the one hand, knowing the exact set of answers is a clear advantage. On the other, the shortlist exists mainly to remove really obscure words and variants (plurals, participles and so on). Most players will figure this out and have a pretty good idea of the possible answers, so having to consider all those obscure words would be an even greater disadvantage. For now, I’m using the shortlist. It’d probably be fairest to collect dictionary headwords and make use of frequency information or something, but this’d take a lot longer. ↩︎
Taking the arithmetic mean of the logs is equivalent to taking the geometric mean of the original values, so minimising the geometric average of words remaining is the same as maximising the information gain. ↩︎
A bit more precisely: reducing the answer set size from 100 to 50 is about as hard as reducing it from 50 to 25, even though in the former case we ruled out more words overall. So a reduction from 100 to 25 is twice as good as 100 to 50, because it’s halving and halving again. The geometric/entropy approach takes this into account. Rejecting one word out of two is very different to rejecting one out of a million, but a simple average treats both cases as equally useful. ↩︎